Convolutional Neural Networks
Warning
This section is very much work in progress!
Convolutional neural networks (CNNs) are an extension ANNs. CNNs are specilized for procesing grid-like topology such as 1-D time-series data, 2-D and 3-D grids of pixels. CNNs has a great application in the field of computer vision, especially in image classification. The name convolutional neural networks indicates that the network performs a mathematical operation called convolution.
Convolutional networks are simply neural networks that use convolution in place of general matrix multiplication in at least one of their layers. This results in three important properties CNNs follows,
Sparse connectivity: Instead of every output unit interacting with every input unit (matrix multiplication), convolutional networks uses a smaller kernal than input during convolution operation. This leads to storing fewer parameters during the convolution operatin and yet preserve all the receptive fields.
Parameter sharing: It implies that the weight applied to one input unit is connected to the other weights applied to the other inputs. The parameter sharing used by theconvolution operation means that rather than learning a separate set of parametersfor every location, we learn only one set.
Equivariance: A function is evuivariance if the input changes, the outputchnages in the same way. This is possible becasue of the the parameter sharing.
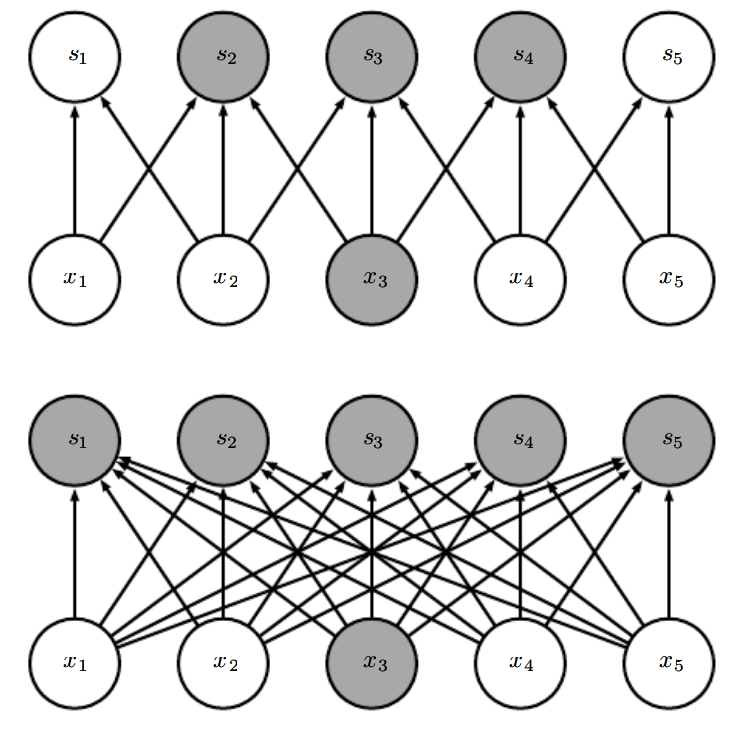
Figure 1: Sparse connectivity, (Top) When s is formed by convolution with a kernel of width 3, only threeinputs affect s3. (Bottom)When s is formed by matrix multiplication, connectivity is nolonger sparse, so all the inputs affect s3.
CNNs are designed after ANNs, which have an input layer, hidden layers, and an output layer. The input layer receives the input vector and transforms it through a series of hidden layers. The last layer is the output layer, and it represents the class scores. CNNs have their neurons arranged in 3 dimensions width, height, and depth, where depth is the number of color channels of the image. The convolution operation is performed on the image pixel values to extract high-level image features such as edges. This gives the advantage of avoiding feature engineering by hand which is necessary in the conventional computer vision algorithms. The ability of automatic feature extraction with the help of convolution layers lets CNNs gives superior results when it comes to image classification.
CNNs are excellent at detecting edges in the images. Unlike the traditional machine learning models, CNNs extract the essential features from the images by performing operations such as convolution and pooling. These extracted features are used to create a high-level blueprint for the given class, which will act as an approximation during the classification task that is performed by a fully connected layer.
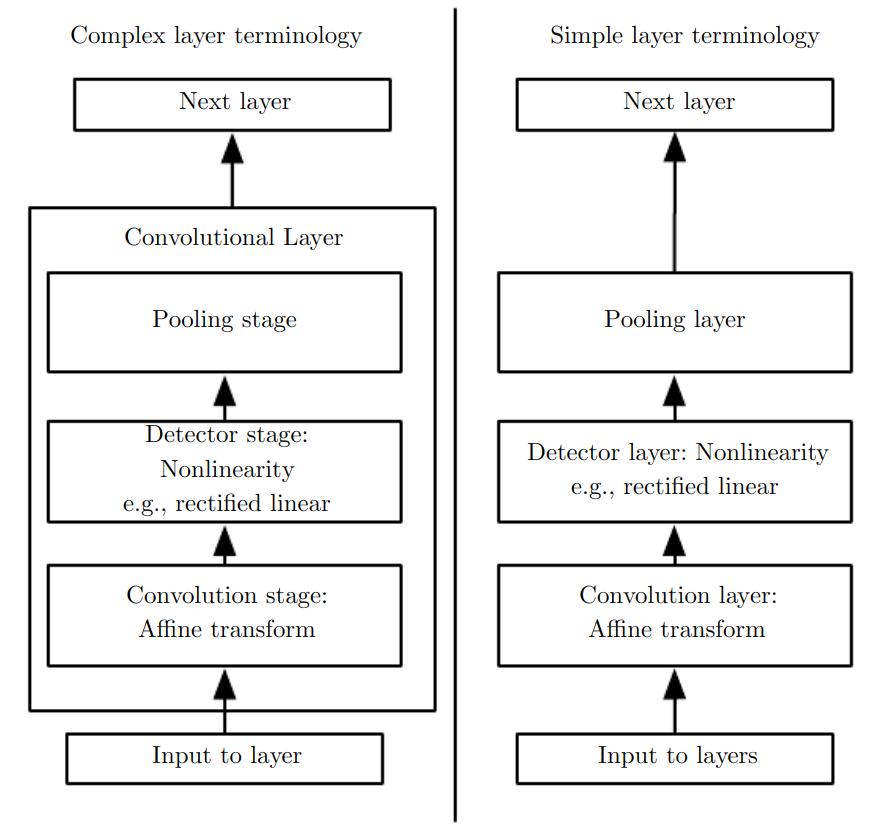
Figure 2: Components of a typical convolutional neural network layer.
Convolution layer
CNNs are named so because of the convolution operation they perform on the image array. Every image is considered as a matrix of pixels. A convolution layer has a filter with some specific filter size that performs convolution operation on the image matrix. A filter is a simple matrix, often a 3 ∗ 3 matrix, which is also referred to as a kernel or a feature detector. The filter is slid over the image from left to right and top to bottom, and a dot product is calculated to obtain the convolution matrix.
Activation layer
An activation layer can either be a linear activation or non-linear activation. Activation function maps the convolution matrix or a feature matrix to have the values in between 0 to 1 or -1 to 1 depending on the function. Nonlinearity is introduced after each convolution layer to make the neural network model to generalize or adapt to different data. Rectified Linear Unit or ReLU, as it commonly referred to as, is the most used activation function in the convolution networks. ReLU activation function converts all the negative values into zeros.
Pooling layer
A pooling layer is used to reduce the dimensionality of each feature matrix but keeps the important features. Spatial pooling is also called subsampling or downsampling. Pooling helps to make representation approximately invaiant to small translations of the input. Invariance to local translation can be a useful property if we care more about wheather some feature is present than exactly where it is. Becasue pooling summarizes the responses over a whole neighborhood, it is possible to use pooling regions spaced k pixels apart rather than 1 pixel apart. This imporves the computational efficiency of the network becasue the next layer roughly k times fewer inputs to process. Pooling operation is performed on the feature matrix with a kernel matrix, usually of size 2 ∗ 2, which would reduce the dimensionality by half.
Fully connected layer
A fully connected layer, as the name referred, is a multi-layer perceptron with all the input neurons and output neurons fully connected to each. Fully connected means that every neuron in the previous layer is connected to every neuron in the next layer. High-level features of the input image can be extracted from the output of the fully connected layer. The output from the fully connected layer is given to an activation layer, either softmax or sigmoid, which would predict the class of the input image.
Note
Figure 1 and 2 are taken from Deep Learing Book